
Les scanners de sites web crachent ce qui ressemble à une soupe d'alphabet à moitié digérée.
Brut.
On pourrait penser à des troubles gastro-intestinaux, mais ce n'est pas tout à fait le cas.
Les scrapers Web traitent les données dans un format non structuré, ce qui permet d'obtenir un document HTML ou un autre type de désordre.
Entrer dans l'analyse des données.
L'analyse des données est une méthode utilisée par les web scrapers pour prendre des pages web et les convertir dans un format plus lisible. Il s'agit d'une étape essentielle du web scraping car, dans le cas contraire, les données seraient difficiles à lire et à analyser.
L'analyse syntaxique est essentielle pour lire le langage informatique. Comme vous le verrez bientôt, il est également essentiel à la compréhension de la réalité.
Analyse définie
Le terme d'analyse syntaxique [des données] vient du mot latin pars (orationis), qui signifie partie du discours. Il peut avoir des significations légèrement différentes selon les branches de la linguistique et de l'informatique.
La psycholinguistique utilise ce terme pour discuter des indices oraux qui aident un locuteur à interpréter des phrases de type "garden path". Dans une autre langue, le terme "parsing" peut également signifier une division ou une séparation.
Wow, il y en a plus que vous ne voulez en savoir, n'est-ce pas ?
Tout cela pour dire qu'analyser signifie diviser un discours en plusieurs parties.
Supposons que nous définissions l'analyse syntaxique dans le langage de la programmation informatique. (Ai-je éveillé votre intérêt ?)
Dans ce cas, vous vous référez à la manière dont vous lisez et traitez une chaîne de symboles, y compris des caractères spéciaux, pour vous aider à comprendre ce que vous essayez d'accomplir.
L'analyse syntaxique est définie différemment par les linguistes et les programmeurs informatiques. Cependant, le consensus général est qu'il s'agit d'analyser les phrases et les relations de cartographie sémantique entre elles. En d'autres termes, l'analyse syntaxique est le filtrage et le classement des structures de données.
Qu'est-ce que l'analyse de données ?
Le terme d'analyse de données décrit le traitement de données non structurées et leur conversion dans un nouveau format structuré.
Le processus d'analyse est omniprésent. Votre cerveau analyse en permanence les données de votre système nerveux.
Mais au lieu que les programmes d'ADN analysent la douleur et le plaisir pour promouvoir la génération de la vie, les analyseurs, dans le contexte de cet article, convertissent les données reçues à partir des résultats du web scraping.
(déception)
Cependant, dans les deux cas, nous devons adapter un format de données pour le rendre compréhensible. Qu'il s'agisse de générer des rapports à partir de chaînes HTML oude filtrer les données sensorielles.
La structure d'un analyseur de données
L'analyse syntaxique des données comporte généralement deux phases essentielles : l'analyse lexicale et l'analyse syntaxique. Ces étapes transforment une chaîne de données non structurées en un arbre de données dont les règles et la syntaxe s'intègrent dans la structure de l'arbre.
Analyse lexicale
Dans sa forme la plus simple, l'analyse lexicale attribue un token à chaque élément de données. Les tokens, ou unités lexicales, comprennent les mots-clés, les délimiteurs et d'autres identifiants.
Supposons que vous ayez une longue file de créatures embarquant sur un navire. Lorsqu'elles passent la porte, chaque créature reçoit un jeton. L'éléphant reçoit le jeton "énorme animal terrestre" et l'alligator le jeton "dangereux amphibien".

Nous savons alors où placer chaque créature sur le bateau, afin que personne ne se blesse pendant les vacances de la croisière au soleil.
Dans le monde de l'analyse syntaxique des données, des unités lexicales sont attribuées aux données non structurées. Par exemple, un mot dans une chaîne HTML recevra un jeton de mot, et ainsi de suite. Les jetons non pertinents contiennent des éléments tels que des parenthèses, des accolades et des points-virgules. Vous pouvez ensuite organiser les données par type de jeton.
Comme vous pouvez le constater, l'analyse lexicale est une étape cruciale pour fournir des données précises à l'analyse syntaxique.
Et de garder les alligators sous contrôle.
Analyse syntaxique
L'analyse syntaxique est le processus qui consiste à construire un arbre d'analyse. Si vous connaissez bien le HTML, cela vous paraîtra facile à comprendre. Imaginons, par exemple, que nous analysions une page web en HTML et que nous créions un modèle objet de document (DOM). Le texte situé entre les balises devient des nœuds enfants ou des branches de l'arbre d'analyse, tandis que les attributs deviennent des propriétés de ces branches.
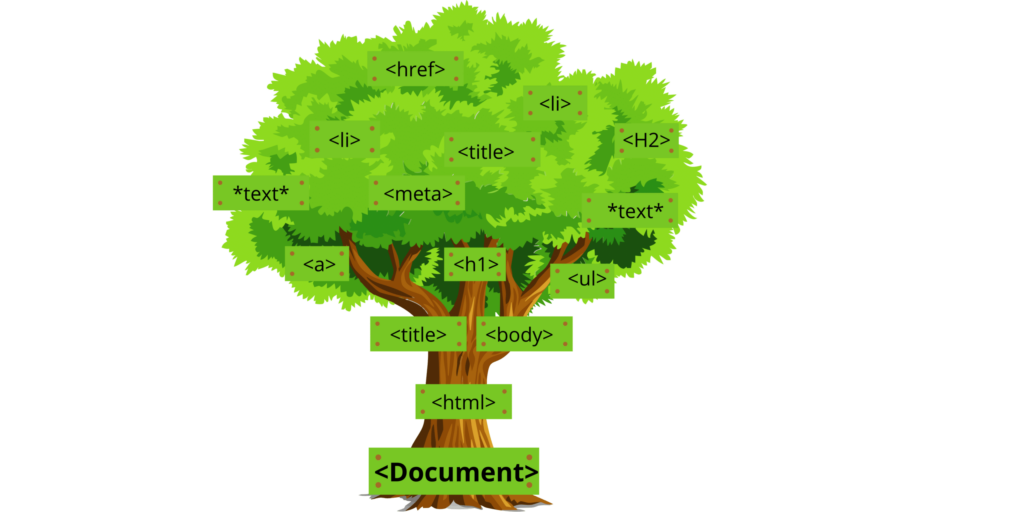
La phase d'analyse syntaxique crée des structures de données qui donnent un sens à ce qui n'était auparavant que des données brutes. Cette phase regroupe également tous les tokens par type - soit des mots-clés, soit des identifiants tels que les parenthèses, les accolades, etc. Ainsi, chaque mot clé a son propre nœud dans la structure plus large construite par votre outil d'analyse syntaxique.
Analyse sémantique
L'analyse sémantique est une étape qui n'est pas mise en œuvre dans la plupart des outils de web scraping. Elle permet d'extraire des données du code HTML en identifiant les différentes parties du discours, comme les noms, les verbes et d'autres rôles dans les phrases.
Mais revenons à l'analyse de notre page web avec des règles syntaxiques pour cette discussion sur l'analyse sémantique. L'analyseur syntaxique décompose chaque phrase dans sa forme correcte. Il continue ensuite à construire des nœuds jusqu'à ce qu'il atteigne la balise de fin ou l'accolade fermante "}" - qui signifie la fin d'un élément.
L'arbre d'analyse syntaxique vous indique les éléments en jeu. Par exemple, les mots qui composent le contenu de votre page web, mais rien sur l'interprétation (sémantique) parce qu'aucune valeur n'a été attribuée lors de l'analyse syntaxique. Pour cela, il faut revenir en arrière et analyser à nouveau les éléments de la page web.
Types d'analyseurs de données
Les analyseurs descendants et ascendants sont deux stratégies différentes pour l'analyse des données.
L'analyse syntaxique descendanteest une méthode qui consiste à comprendre les phrases en commençant par leurs éléments les plus petits, puis en remontant progressivement vers le haut. On parle alors d'« approche de la soupe primordiale ». Elle s'apparente beaucoup à l'analyse syntaxique, qui décompose les constituants d'une phrase. Les analyseurs LL constituent un exemple de ce type d'analyseur syntaxique.
L'analyse syntaxique ascendantecommence par la fin et remonte progressivement, en identifiant d'abord les éléments les plus fondamentaux. Les analyseurs LR constituent un exemple de ce type d'analyseur.
Construire ou acheter ?
Comme pour les macaronis au fromage, il est parfois plus économique de faire soi-même que d'acheter le produit. En ce qui concerne les analyseurs de données, la question n'est pas aussi facile à résoudre. Il y a davantage d'éléments à prendre en compte lorsque l'on choisit de construire ou d'acheter des outils d'extraction de données. Examinons le potentiel et les résultats des deux options.

Acheter un analyseur de données
Le web regorge de technologies d'analyse syntaxique. Vous pouvez acheter un analyseur et obtenir rapidement des résultats à un prix abordable. L'inconvénient de cette approche est que si vous souhaitez que votre logiciel fonctionne sur différentes plateformes ou à d'autres fins, vous devrez acheter plus d'un produit.
Cela peut s'avérer coûteux au fil du temps et, en fonction des objectifs et des ressources de votre équipe, il se peut que ce ne soit pas pratique. Il existe des outils d'analyse de données gratuits et payants. Cependant, tout dépend des besoins de votre équipe. Gardez donc ces éléments à l'esprit lorsque vous envisagez d'acheter un service web plutôt que de développer vous-même un code personnalisé.
Les pros de l'externalisation
- L'achat d'un analyseur de données vous donne accès aux technologies d'analyse d'une organisation spécialisée dans l'extraction de données. Davantage de ressources sont consacrées à l'amélioration et à l'efficacité de l'analyse syntaxique des données.
- Vous disposez de plus de temps et de ressources car vous n'avez pas besoin d'investir dans une équipe ou de passer du temps à maintenir votre propre analyseur. Il y a moins de risques que vous rencontriez des problèmes.
Les inconvénients de l'externalisation
- Vous n'aurez probablement pas assez d'occasions de personnaliser votre analyseur de données pour répondre aux besoins de votre entreprise.
- Le coût de toute personnalisation peut survenir si vous externalisez votre programmation.
Construire un analyseur de données
Construire son propre analyseur de données est bénéfique, mais cela peut consommer trop d'énergie et de ressources. En particulier si vous avez besoin d'un processus d'analyse complexe pour analyser de grandes structures de données. Le développement et la maintenance nécessitent une équipe de développement compétente et expérimentée. La dernière fois que j'ai vérifié, un data scientist n'est pas bon marché !

La construction d'un analyseur de données nécessite des compétences telles que
- Traitement du langage naturel
- Récupération de données
- Développement web
- Construction d'un arbre d'analyse
Vous ou votre équipe devrez maîtriser les langages de programmation et les technologies d'analyse syntaxique.
Professionnels internes
- Les analyseurs internes sont efficaces parce qu'ils sont personnalisables.
- En confiant votre analyseur de données à un prestataire interne, vous aurez un contrôle total sur la maintenance et les mises à jour.
- Si l'analyse de données est une composante importante de votre activité, elle sera plus rentable à long terme.
Vous avez également la possibilité d'utiliser votre propre produit n'importe où après l'avoir développé, ce qui est essentiel lorsque vous créez des analyseurs de données plutôt que d'en acheter un. Si vous achetez un analyseur, vous êtes lié à sa plateforme, comme Google Sheets.
Contre en interne
- La maintenance, la mise à jour ou le test de votre propre analyseur syntaxique prend du temps. Par exemple, l'édition et le test de votre propre analyseur nécessitent un serveur capable de supporter les ressources nécessaires.
De quels outils avez-vous besoin pour l'analyse des données ?

Si vous souhaitez construire un scraper web, vous aurez besoin d'une bibliothèque d'analyse de données avec le langage de programmation adéquat. Ruby, Python, JavaScript (Node.js), Java et C++ sont des options qui dépendent du langage de programmation que vous souhaitez utiliser pour votre projet d'analyse de données.
Ces langages de programmation s'utilisent avec le framework de crawling Nokogiri ou avec des frameworks web tels que Django ou Flask, dans le cas de Python.
Sinon, si vous optez pour Ruby, vous avez le choix entre Nokigiri et Cheerio, qui propose une API parfaitement compatible avec les applications web Rails.
Pour la programmation Node.js, on peut utiliser JSoup, mais Scrapy constitue également une autre option pour l'exploration du Web dans ce contexte !
Regardons de plus près :

Nokogiri
Nokogiri vous permet de travailler avec HTML avec Ruby. Il dispose d'une API similaire aux autres paquets d'autres langages, qui vous permet d'interroger les données que vous récupérez à partir du web scraping. Il traite chaque document avec un cryptage par défaut qui ajoute une couche de sécurité supplémentaire. Vous pouvez utiliser Nokogiri avec des frameworks web tels que Rails, Sinatra et Titanium.

Cheerio
Cheerio est une excellente option pour l'analyse des données Node.js. Il fournit une API que vous pouvez utiliser pour explorer et modifier la structure des données de vos résultats d'analyse web. Il n'a pas de rendu visuel, n'applique pas de CSS et ne charge pas de ressources externes comme le ferait un navigateur. Cheerio présente de nombreux avantages par rapport à d'autres frameworks, notamment une meilleure gestion des langages de balisage brisés que la plupart des alternatives, tout en offrant des vitesses de traitement élevées !

JSoup
JSoup vous permet d'utiliser des données graphiques HTML via une API pour récupérer, extraire et manipuler des URL. Il fonctionne comme un navigateur et comme un analyseur de pages web. Même s'il est souvent difficile de trouver d'autres options Java open-source, il vaut vraiment la peine d'être considéré.

BeautifulSoup
BeautifulSoup est une bibliothèque Python permettant d'extraire des données à partir de fichiers HTML et XML. Ce framework de crawling est très utile pour analyser les données du Web. Il est compatible avec des frameworks Web tels que Django et Flask.

Ferraille
Scrapy est un framework de crawling web écrit en Python et disponible sur PyPI. Il facilite grandement la création de robots d'indexation tout en étant suffisamment puissant pour réaliser des tâches personnalisées. Scrapy peut également être utilisé comme bibliothèque de web scraping à part entière.

Parsimonieux
La bibliothèque Parsimonious utilise la grammaire d'expression d'analyse (PEG). Vous pouvez utiliser cet analyseur dans des applications Python ou Ruby on Rails. Les PEG sont couramment utilisées dans certains frameworks web et analyseurs en raison de leur simplicité par rapport aux grammaires sans contexte. Elles présentent toutefois des limites lorsqu'il s'agit d'analyser des langages ne comportant pas d'espaces entre certains mots, comme c'est le cas dans les exemples de code C++.

LXML
Lxml est un autre analyseur XML pour Python qui permet de parcourir la structure des données issues de pages web. Il intègre également de nombreuses fonctionnalités supplémentaires pour l'analyse HTML et les requêtes XPath, ce qui peut s'avérer utile lors de l'extraction de données sur le web. Il a été utilisé dans de nombreux projets par la NASA et Spotify ; sa popularité parle donc d'elle-même !
Laissez-vous inspirer par ces options avant de choisir celle qui conviendra le mieux à votre équipe !
Prévenir les blocages liés au web scraping
Le blocage du web scraping est un problème courant. Certaines personnes ne veulent tout simplement pas subir la charge et les risques liés aux visiteurs robots. (Ces fichus bots !) Pour en savoir plus, cliquez ici.
La solution consiste à utiliser des proxys résidentiels rotatifs. De nombreuses API de web scraping en intègrent, mais vous devez bien maîtriser le fonctionnement des proxys si vous envisagez de développer votre propre analyseur syntaxique.
Cet article vous explique tout ce qu'il faut savoir sur les proxys résidentiels et comment vous pouvez les utiliser pour l'extraction de données.
Cas d'utilisation de l'analyse syntaxique des données
Vous connaissez maintenant les avantages de l'utilisation d'un analyseur syntaxique pour convertir les pages web dans un format facile à lire. Examinons quelques cas d'utilisation qui pourraient aider votre équipe.

Sécurité du web
Pour protéger vos données des pirates informatiques, vous pouvez crypter les informations sensibles contenues dans vos fichiers de données avant de les envoyer sur Internet ou de les stocker sur des appareils. Vous pouvez analyser les journaux de données et rechercher des traces de logiciels malveillants ou d'autres virus.

Développement web
Le web devient de plus en plus complexe, il est donc important d'analyser les données et d'utiliser des outils de journalisation pour comprendre comment les utilisateurs interagissent avec les pages web. Le secteur du développement web continuera à se développer à mesure que les applications mobiles prendront une place importante dans nos vies.

Extraction des données
L'analyse des données est une pratique cruciale pour l'extraction des données. Le web scraping peut prendre beaucoup de temps, et il est important d'analyser les données dès que possible, afin de respecter le calendrier du projet. Pour tout projet de développement web ou d'exploration de données, vous devez savoir comment utiliser correctement un analyseur de données !

Analyse des investissements
Les investisseurs peuvent exploiter efficacement l'agrégation de données afin de prendre de meilleures décisions commerciales. Les investisseurs, les fonds spéculatifs ou autres qui évaluent les entreprises en phase de démarrage, prédisent les bénéfices et contrôlent même le sentiment social s'appuient sur des techniques d'extraction de données robustes.
Les outils de scraping et d'analyse de données permettent de gagner en rapidité et en efficacité. Ils optimisent le flux de travail et vous permettent de réaffecter vos ressources à d'autres tâches ou de vous concentrer sur des analyses de données plus approfondies, telles que la recherche sur les actions et l'analyse concurrentielle. Pour plus d'informations sur les outils de scraping,cliquez ici.

Analyse du registre
L'analyse du registre est une technique essentielle et puissante pour détecter les logiciels malveillants dans une image. Outre les mécanismes de persistance, les logiciels malveillants comportent souvent d'autres traces que vous pouvez rechercher. Ces traces comprennent notamment les valeurs associées à la clé MUICache, les fichiers de prélecture, les fichiers de données Dr. Watson et d'autres objets. Ces éléments, ainsi que différents types de logiciels malveillants, peuvent fournir des indices dans des cas où les programmes antivirus ne parviennent pas à les détecter.

Immobilier
Un analyseur syntaxique peut être utile à une société immobilière en lui fournissant des coordonnées, des adresses de propriétés, des données sur les flux de trésorerie et des sources de prospects.

Finances et comptabilité
L'exploitation des données est utilisée pour analyser les scores de crédit et les données des portefeuilles d'investissement et pour obtenir de meilleures informations sur les interactions des clients avec d'autres utilisateurs. Les sociétés financières utilisent l'analyse syntaxique pour déterminer le taux et la période de remboursement de la dette après avoir extrait les données.
Vous pouvez également utiliser l'analyse de données à des fins de recherche pour déterminer les taux d'intérêt, le taux de retour des paiements de prêts et le taux d'intérêt des dépôts bancaires.

Optimisation du flux de travail des entreprises
Les analyseurs de données sont utilisés par les entreprises pour analyser les données non structurées et les transformer en informations utiles. Le data mining permet aux entreprises d'optimiser les flux de travail et de tirer parti d'une analyse approfondie des données. Vous pouvez utiliser l'analyse syntaxique dans la publicité, le marketing social, la gestion des médias sociaux et d'autres applications commerciales.

Transport maritime et logistique
Les entreprises qui fournissent des biens et des services sur le web utilisent le scraping de données pour extraire les détails de la facturation. Elles utilisent des analyseurs syntaxiques pour organiser les étiquettes d'expédition et vérifier que le formatage a été corrigé.

Intelligence artificielle
Le traitement du langage naturel (TLN) est à la pointe de l'intelligence artificielle et de l'apprentissage automatique. Il s'agit d'un domaine de l'analyse des données qui permet aux ordinateurs de comprendre le langage humain.
Il y a bien d'autres utilisations. Au fur et à mesure que nous avançons dans l'ère numérique, la différence entre le code informatique et les données organiques se réduit de plus en plus.
Pour en savoir plus sur le web scraping et l'analyse de données, consultez les autres articles de notre blog.


